(1) 비디오 신호의 중복 정보
디지털 비디오 녹화의 YUV 구성 요소 형식을 예로 들어 YUV는 각각 밝기와 두 가지 색상 차이 신호를 나타냅니다. 예를 들어, 기존 pal TV 시스템의 경우 휘도 신호의 샘플링 주파수는 13.5mhz입니다. 크로마 신호의 주파수 대역은 일반적으로 6.75mhz 또는 3.375mhz 인 밝기 신호의 절반 이하입니다. 4 : 2 : 2의 샘플링 주파수를 예로 들면 Y 신호는 13.5mhz를 채택하고, 크로마 신호 U와 V는 6.75mhz로 샘플링하고 샘플링 신호는 8bit로 양자화 한 다음 디지털 비디오의 코드 율을 계산할 수 있습니다. 다음과 같이 :
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216Mbit / s
이렇게 많은 양의 데이터를 직접 저장하거나 전송하면 압축 기술을 사용하여 비트율을 낮추기가 어려울 것입니다. 디지털 비디오 신호는 두 가지 기본 조건에 따라 압축 될 수 있습니다.
L. 데이터 중복. 예를 들어, 공간 중복성, 시간 중복성, 구조 중복성, 정보 엔트로피 중복성 등, 즉 이미지의 픽셀간에 강한 상관 관계가 있습니다. 이러한 중복성을 제거한다고해서 정보가 손실되는 것은 아니며 무손실 압축입니다.
L. 시각적 중복. 밝기 판별 임계 값, 시각적 임계 값과 같은 인간 눈의 일부 특성은 밝기 및 채도에 대한 민감도가 다르므로 코딩에 적절한 오류를 도입 할 수 없으며 감지되지 않습니다. 인간의 눈의 시각적 특성을 사용하여 특정 객관적인 왜곡이있는 데이터 압축을 교환 할 수 있습니다. 이 압축은 손실이 있습니다.
디지털 비디오 신호의 압축은 위의 두 가지 조건을 기반으로하므로 비디오 데이터가 크게 압축되어 전송 및 저장에 도움이됩니다. 디지털 비디오 압축의 일반적인 방법은 혼합 코딩으로, 변환 코딩, 동작 추정 및 동작 보상, 엔트로피 코딩을 결합하여 코딩을 압축합니다. 일반적으로 변환 코딩은 이미지의 프레임 내 중복성을 제거하기 위해 사용되며, 움직임 추정 및 움직임 보상은 이미지의 프레임 간 중복성을 제거하기 위해 사용되며, 엔트로피 코딩은 압축 효율을 더욱 향상시키기 위해 사용됩니다. 다음 세 가지 압축 코딩 방법이 간략하게 소개됩니다.
(a) 압축 코딩 방법
(b) 변환 코딩
변환 코딩의 기능은 공간 도메인에 설명 된 이미지 신호를 주파수 도메인으로 변환 한 다음 변환 된 계수를 인코딩하는 것입니다. 일반적으로 이미지는 공간에서 강한 상관 관계를 가지며 주파수 영역으로의 변환은 역 상관과 에너지 집중을 실현할 수 있습니다. 일반적인 직교 변환에는 이산 푸리에 변환, 이산 코사인 변환 등이 포함됩니다. 이산 코사인 변환은 디지털 비디오 압축에 널리 사용됩니다.
이산 코사인 변환을 DCT 변환이라고합니다. L * l의 이미지 블록을 공간 영역에서 주파수 영역으로 변환 할 수 있습니다. 따라서 DCT 기반의 영상 압축 및 코딩 과정에서 영상은 비 중첩 영상 블록으로 분할되어야한다. 이미지의 크기가 1280 * 720이라고 가정하고, 그리드 형태로 겹치지 않고 160 * 90 크기의 8 * 8 이미지 블록으로 나뉩니다. 그런 다음 각 이미지 블록에 대해 DCT 변환을 수행 할 수 있습니다.
블록이 분할 된 후 각 8 * 8 포인트 이미지 블록은 DCT 인코더로 전송되고 8 * 8 이미지 블록은 공간 영역에서 주파수 영역으로 변환됩니다. 아래 그림은 숫자가 각 픽셀의 밝기 값을 나타내는 8 * 8 이미지 블록의 예를 보여줍니다. 그림에서 볼 수 있듯이이 이미지 블록의 각 픽셀의 밝기 값은 상대적으로 균일하며, 특히 인접한 픽셀의 밝기 값은 그다지 크지 않아 이미지 신호가 강한 상관 관계를 가지고 있음을 나타냅니다.
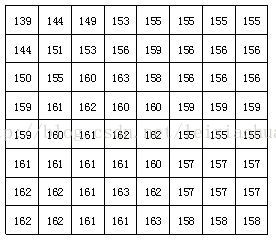
실제 8 * 8 이미지 블록
다음 그림은 위 그림에서 이미지 블록의 DCT 변환 결과를 보여줍니다. 그림에서 볼 수 있듯이 DCT 변환 후 좌측 상단의 저주파 계수는 많은 에너지를 집중시키는 반면 우측 하단의 고주파 계수의 에너지는 매우 작습니다.
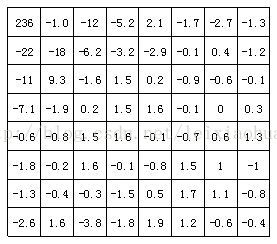
DCT 변환 후 이미지 블록의 계수
신호는 DCT 변환 후에 정량화되어야합니다. 인간의 눈은 물체의 전체적인 밝기와 같은 이미지의 저주파 특성에 민감하기 때문에 이미지의 고주파 세부 사항에는 민감하지 않으므로 전송 과정에서 고주파 정보는 덜 전송되거나 전송되지 않을 수 있습니다. 저주파 부분. 양자화 과정은 저주파 영역의 계수를 정량화하고 고주파 영역의 계수를 대략 양자화하여 정보 전송을 줄여 사람의 눈에 민감하지 않은 고주파 정보를 제거합니다. 따라서 양자화는 손실 압축 프로세스이며 비디오 압축 코딩에서 품질 손상의 주요 원인입니다.
정량화 과정은 다음 공식으로 표현할 수 있습니다.

그중 FQ (U, V)는 양자화 후의 DCT 계수를 나타냅니다. f (U, V)는 양자화 전 DCT 계수를 나타냅니다. Q (U, V)는 양자화 가중 행렬을 나타내고; q는 양자화 단계이고; round는 통합을 의미하며 출력되는 값은 가장 가까운 정수 값으로 간주됩니다.
양자화 계수를 합리적으로 선택하면 변환 된 영상 블록을 양자화 한 결과가 그림과 같습니다.

정량화 후 DCT 계수
대부분의 DCT 계수는 양자화 후 0으로 변경되는 반면 소수의 계수 만 XNUMX이 아닌 값입니다. 현재는 이러한 XNUMX이 아닌 값만 압축하고 인코딩하면됩니다.
(b) 엔트로피 코딩
엔트로피 코딩은 코딩 후 평균 코드 길이가 소스의 엔트로피 값에 가깝기 때문에 명명됩니다. 엔트로피 코딩은 VLC (가변 길이 코딩)에 의해 구현됩니다. 기본 원리는 통계적으로 더 짧은 평균 코드 길이를 얻기 위해 소스에서 확률이 높은 심볼에 짧은 코드를 부여하고 발생 확률이 작은 심볼에 긴 코드를 부여하는 것입니다. 가변 길이 코딩에는 일반적으로 호프만 코드, 산술 코드, 실행 코드 등이 포함됩니다. 실행 길이 코딩은 매우 간단한 압축 방법이며 압축 효율성이 높지 않지만 코딩 및 디코딩 속도가 빠르며 특히 여전히 널리 사용되고 있습니다. 인코딩 변환 후 실행 길이 코딩을 사용하면 좋은 효과가 있습니다.
첫째, 양자화 기의 출력 DC 계수 바로 다음의 AC 계수는 Z 형으로 스캔되어야합니다 (화살표 선으로 표시됨). Z 스캔은 XNUMX 차원 양자화 계수를 XNUMX 차원 시퀀스로 변환 한 다음 실행 길이 코딩을 수행합니다. 마지막으로 Hoffman 코딩과 같은 다른 가변 길이 코드를 사용하여 인코딩을 실행 한 후 데이터를 인코딩합니다. 이러한 종류의 가변 길이 코딩을 통해 코딩의 효율성이 더욱 향상됩니다.
(c) 움직임 추정 및 움직임 보상
모션 추정 및 모션 보상은 이미지 시퀀스의 시간 방향 상관 관계를 제거하는 효과적인 방법입니다. 위에서 설명한 DCT 변환, 양자화 및 엔트로피 코딩 방법은 하나의 프레임 이미지를 기반으로합니다. 이러한 방법을 통해 이미지의 픽셀 간의 공간적 상관 관계를 제거 할 수 있습니다. 사실, 영상 신호는 공간적 상관 관계 외에도 시간적 상관 관계가 있습니다. 예를 들어, 뉴스 공동 방송과 같이 배경이 정적 인 디지털 영상과 영상의 본체 움직임이 작은 경우 각 영상의 차이가 매우 적고 영상 간의 상관 관계가 매우 크다. 이 경우 각 프레임 이미지를 개별적으로 인코딩 할 필요는 없지만 인접한 비디오 프레임의 변경된 부분 만 인코딩하여 데이터 양을 더 줄일 수 있습니다. 이 작업은 모션 추정과 모션 보상으로 실현됩니다.
모션 추정 기술은 일반적으로 현재 입력 이미지를 서로 겹치지 않는 여러 개의 작은 이미지 서브 블록으로 분할합니다. 예를 들어, 프레임 이미지의 크기는 1280 * 720입니다. 첫째, 40 *의 45 * 16 이미지 블록으로 분할됩니다. 그리드 형태로 서로 겹치지 않는 16 개의 크기로, 이전 이미지 또는 후자 이미지의 검색 창 범위 내에서 각 이미지 블록에 대한 블록을 찾아 하나의 이미지 블록을 찾기 위해 검색 창 가장 유사한 이미지 블록. 검색 프로세스를 모션 추정이라고합니다. 가장 유사한 이미지 블록과 이미지 블록 사이의 위치 정보를 계산하여 움직임 벡터를 얻을 수 있습니다. 이러한 방식으로, 참조 영상 움직임 벡터가 가리키는 가장 유사한 영상 블록에서 현재 영상 블록을 빼서 잔상 블록을 얻을 수있다. 잔상 블록의 각 픽셀 값이 매우 작기 때문에 압축 코딩에서 더 높은 압축 비율을 얻을 수 있습니다. 이 빼기 과정을 동작 보정이라고합니다.
부호화 과정에서 움직임 추정과 움직임 보상을 위해 참조 영상이 필요하기 때문에 참조 영상을 선택하는 것이 매우 중요하다. 일반적으로 인코더는 서로 다른 참조 이미지에 따라 입력 된 각 프레임 이미지를 I (인트라) 프레임, B (안내 예측) 프레임 및 P (예측) 프레임의 세 가지 유형으로 나눕니다. 그림과 같이.
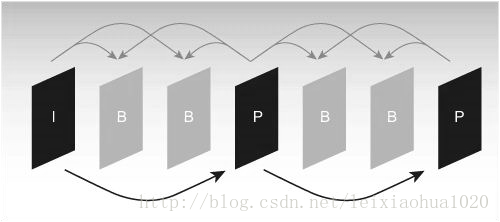
일반적인 I, B, P 프레임 구조 시퀀스
그림에서 볼 수 있듯이 I frame은 코딩을 위해 프레임의 데이터 만 사용하며 코딩 과정에서 움직임 추정 및 움직임 보상이 필요하지 않습니다. 분명히 I 프레임은 시간 방향의 상관 관계를 제거하지 않기 때문에 압축 비율이 상대적으로 낮습니다. 코딩 과정에서 P 프레임은 움직임 보상을위한 참조 이미지로 전면 I 프레임 또는 P 프레임을 사용하며 실제로 현재 이미지와 참조 이미지의 차이를 인코딩합니다. B 프레임의 인코딩 모드는 P 프레임과 유사하지만, 유일한 차이점은 코딩 과정에서 예측하기 위해 전면 I 프레임 또는 P 프레임과 이후의 I 프레임 또는 P 프레임을 사용해야한다는 것입니다. 따라서 각 P 프레임 코딩은 하나의 프레임 이미지를 참조 이미지로 사용해야하고 프레임 B는 두 개의 프레임을 참조로 사용해야합니다. 반면 B 프레임은 P 프레임보다 압축률이 높습니다.
(d) 혼합 코딩
이 백서는 비디오 압축 및 코딩에서 몇 가지 중요한 방법을 소개합니다. 실제 적용에서 이러한 방법은 분리되지 않으며 일반적으로 최상의 압축 효과를 얻기 위해 결합됩니다. 다음 그림은 하이브리드 코딩의 모델을 보여줍니다 (즉, 변환 코딩 + 모션 추정 및 모션 보상 + 엔트로피 코딩). 이 모델은 MPEG1, MPEG2, H.264 및 기타 표준에서 널리 사용되며 그림에서 볼 수 있듯이 현재 입력 이미지를 먼저 블록으로 나누고 블록에서 얻은 이미지의 블록을 움직임 보상 후 예측 영상을 통해 차이 영상 x를 획득 한 다음, 차이 영상 블록에 대해 DCT 변환 및 양자화를 수행합니다. 양자화 된 출력 데이터에는 두 개의 다른 위치가 있습니다. 하나는 코딩을 위해 엔트로피 인코더로 보내는 것이고, 인코딩 된 코드 스트림은 장치의 캐시 저장으로 출력되고 전송을 기다립니다. 또 다른 애플리케이션은 신호 x '의 변경을 카운터 화하고 역방향으로 변경하는 것입니다. 이는 새로운 예측 이미지 신호를 얻기 위해 움직임 보상으로 이미지 블록 출력을 추가하고 새로운 예측 이미지 블록을 프레임 메모리로 보냅니다.



|
|
|
|
송신기 커버 얼마나 (긴)?
전송 범위는 다양한 요인에 따라 달라진다. 진정한 거리 건물 및 다른 장애물이, 수신기의 감도는 수신기의 안테나 등의 환경을 이용하여 높이를 설치하는 안테나, 안테나 이득에 기초한다. 안테나는 더 높은 설치 및 시골에서 사용하여 거리 것입니다 훨씬 더 멀리.
예 5W FM 송신기는 도시와 고향에 사용
나는 그의 고향 GP 안테나와 미국 고객의 사용 5W의 FM 송신기를 가지고 있고, 그는 차에 그것을 테스트, 그것은 10km (6.21mile)를 커버한다.
나는 5km (2mile)에 대한 커버, 내 고향 GP 안테나와 1.24W의 FM 송신기를 테스트합니다.
나는 광주 시내에서 GP 안테나와 5W의 FM 송신기를 테스트, 그것은 단지 300meter (984ft)에 대해 다룹니다.
다음은 다른 전원 FM 송신기의 대략적인 범위입니다. (범위는 직경)
0.1W ~ 5W FM 송신기 : 100M ~ 1KM
5W ~ 15W FM Ttransmitter : 1KM ~ 3KM
15W ~ 80W FM 송신기 : 3KM ~ 10KM
80W ~ 500W FM 송신기 : 10KM ~ 30KM
500W ~ 1000W FM 송신기 : 30KM ~ 50KM
1KW ~ 2KW FM 송신기 : 50KM ~ 100KM
2KW ~ 5KW FM 송신기 : 100KM ~ 150KM
5KW ~ 10KW FM 송신기 : 150KM ~ 200KM
어떻게 송신기를 위해 저희에게 연락하는 방법?
+ 8618078869184 나에게 전화를하거나
나에게 이메일을 보내 [이메일 보호]
지금까지 당신은 직경 커버 할 1.How?
당신의 2.How 높이 타워?
당신은 3.Where에서입니까?
그리고 우리는 당신에게 더 많은 전문적인 조언을 제공 할 것입니다.
회사 소개
FMUSER.ORG는 RF 무선 전송 / 스튜디오 비디오 오디오 장비 / 스트리밍 및 데이터 처리에 중점을 둔 시스템 통합 회사입니다. 랙 통합을 통해 설치, 시운전 및 교육에 이르는 모든 조언과 컨설팅을 제공합니다.
우리는 FM 송신기, 아날로그 TV 송신기, 디지털 TV 송신기, VHF UHF 송신기, 안테나, 동축 케이블 커넥터, STL, On Air 처리, 스튜디오 용 방송 제품, RF 신호 모니터링, RDS 인코더, 오디오 프로세서 및 원격 사이트 제어 장치, IPTV 제품, 비디오 / 오디오 인코더 / 디코더는 대규모 국제 방송 네트워크 및 소형 개인 스테이션 모두의 요구 사항을 모두 충족하도록 설계되었습니다.
우리의 솔루션에는 FM 라디오 방송국 / 아날로그 TV 방송국 / 디지털 TV 방송국 / 오디오 비디오 스튜디오 장비 / 스튜디오 송신기 링크 / 송신기 원격 측정 시스템 / 호텔 TV 시스템 / IPTV 라이브 방송 / 스트리밍 라이브 방송 / 화상 회의 / CATV 방송 시스템이 있습니다.
우리는 높은 신뢰성과 높은 성능이 시스템과 솔루션에 매우 중요하다는 것을 알고 있기 때문에 모든 시스템에 첨단 기술 제품을 사용하고 있습니다. 동시에 우리는 또한 매우 합리적인 가격으로 제품 시스템을 확인해야합니다.
우리는 공공 및 상업 방송사, 통신 사업자 및 규제 당국의 고객을 보유하고 있으며, 소규모, 지역 및 지역 방송인 수백 명에게 솔루션과 제품을 제공합니다.
FMUSER.ORG는 15 년 이상 수출 해 왔으며 전 세계에 고객을두고 있습니다. 이 분야에서 13 년의 경험을 바탕으로 고객의 모든 종류의 문제를 해결하는 전문 팀이 있습니다. 우리는 전문적인 제품 및 서비스의 매우 합리적인 가격을 제공하기 위해 최선을 다하고 있습니다. 이메일 연락처 : [이메일 보호]
우리의 공장

우리는이 현대화 공장. 당신은 당신이 중국에 올 때 우리의 공장을 방문에 오신 것을 환영합니다.

현재, 이미이 있습니다 1095 고객 전 세계적으로 우리의 광저우 톈허 사무실을 방문했다. 당신이 중국에 오는 경우에, 당신은 우리를 방문 환영합니다.
박람회

이 2012 글로벌 소스에 우리의 참여입니다 홍콩 전자 박람회 . 전 세계에서 고객 마지막으로 함께 얻을 수있는 기회가있다.
Fmuser 어디에 있습니까?
이 번호를 검색 할 수 있습니다. " 23.127460034623816,113.33224654197693 "Google지도에서 fmuser 사무실을 찾을 수 있습니다.
FMUSER 광저우 사무소는 인 톈허 지구에 광저우의 중심 . 대단히 ... ~로 캔톤 페어 , 광저우 기차역, xiaobei 도로 및 dashatou 만 필요 10 분 하면은 걸릴 택시 . 전 세계에 오신 것을 환영합니다 친구들이 방문하여 협상.
연락처 : 스카이 블루
핸드폰 : + 8618078869184
WhatsApp: + 8618078869184
Wechat : + 8618078869184
이메일: [이메일 보호]
QQ : 727926717
스카이프 : sky198710021
주소 : No.305 룸 HuiLan 건물 No.273 Huanpu 도로 광저우 중국 우편 번호 : 510620을
|
|
|
|
영어: 우리는 PayPal, 신용 카드, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer와 같은 모든 지불을 수락합니다. 질문이 있으시면 저에게 연락하십시오. [이메일 보호] 또는 WhatsApp + 8618078869184
-
페이팔.  www.paypal.com www.paypal.com
우리는 당신이 우리의 항목을 구매 페이팔을 사용하는 것이 좋습니다, 페이팔은 인터넷에서 살 수있는 안전한 방법입니다.
상단에 우리의 항목 목록 페이지 하단의 모든 지불하는 페이팔 로고가 있습니다.
신용 카드.당신은 페이팔이없는,하지만 당신은 신용 카드를 사용하는 경우, 당신은 또한 당신의 신용 카드로 지불하는 노란색 페이팔 버튼을 클릭 할 수 있습니다.
-------------------------------------------------- -------------------
그렇지 신용 카드를 가지고 페이팔 accout을 가지고있는 페이팔 계정이나 어려움이없는 경우에, 당신은 다음을 사용할 수 있습니다 :
웨스턴 유니언.  www.westernunion.com www.westernunion.com
웨스턴 유니언 (Western Union)에 의해 나에게 지불 :
이름 / 지명 : Yingfeng
성 / 성 / 호칭 : 장
성명 : Yingfeng Zhang
국가 : 중국
도시 : 광저우
|
-------------------------------------------------- -------------------
T / T. 에 의해 지불 T / T (은행 송금 / 전신환 / 은행 송금)
최초 은행 정보 (회사 계좌) :
SWIFT BIC : BKCHHKHHXXX
은행 이름 : BANK OF CHINA (HONG KONG) LONGITED, HONG KONG
은행 주소 : BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONGKONG
은행 코드 : 012
계정 이름 : FMUSER INTERNATIONAL GROUP LIMITED
계정 없음. : 012-676-2-007855-0
-------------------------------------------------- -------------------
두 번째 은행 정보 (회사 계좌) :
수혜자 : Fmuser International Group Inc
계좌 번호 : 44050158090900000337
수익자 은행 : 중국 건설 은행 광동 지점
SWIFT 코드 : PCBCCNBJGDX
주소 : NO.553 Tianhe Road, Guangzhou, Guangdong, Tianhe District, China
** 참고 : 은행 계좌로 송금 할 때 비고란에 아무것도 쓰지 마십시오. 그렇지 않으면 국제 무역 비즈니스에 대한 정부 정책으로 인해 대금을받을 수 없습니다.
|
|
|
|
* 그것은 때 지불 맑은 날 작업 1-2에 전송됩니다.
* 우리는 당신의 페이팔 주소로 보내드립니다. 당신이 주소를 변경하려면, 내 이메일에 정확한 주소와 전화 번호를 보내 주시기 바랍니다 [이메일 보호]
패키지가 2kg 미만인 경우 *, 우리가 포스트 항공 우편을 통해 배송됩니다, 그것은 당신의 손에 15-25days 정도 소요됩니다.
패키지가 2kg보다 더 많은 경우, 우리는 EMS, DHL, UPS를 통해 배송됩니다, 페덱스 빠르고 신속 배송, 그것은 당신의 손에 ~ 7에 대해 15days를 취할 것입니다.
100kg보다 패키지 많은 경우에, 우리는 DHL 또는 항공화물을 통해 보내드립니다. 그것은 당신의 손에 ~ 3에 대해 7days를 취할 것입니다.
모든 패키지는 중국 광저우 형성한다.
* 패키지는 "선물"로 발송되며 가능한 한 적어 지므로 구매자는 "TAX"를 지불 할 필요가 없습니다.
* 선박 후, 우리는 당신에게 E 메일을 보내고 당신에게 추적 번호를 제공합니다.
|
|
|
보증을 위해.
저희에게 연락하십시오 --- >> 저희에게 품목을 돌려 보내십시오 --- >> 다른 교체를 받고 보내십시오.
이름 : 리우 시아 오시아
주소 : 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu 광저우 중국.
우편 번호 : 510620
전화 : + 8618078869184
이 주소로 돌아가서 노트에 페이팔 주소, 이름, 문제를 작성 해주세요 : |
|













